
Surface Realization Shared Task 2018
The Generation Challenges
Task description
As in SR’11, the proposed shared task comprises two tracks with different levels of complexity:- Shallow Track : This track starts from genuine UD structures from which word order information has been removed and the tokens have been lemmatized, i.e., from unordered dependency trees with lemmatized nodes that hold PoS tags and morphological information as found in the original annotations. It consists in determining the word order and inflecting words.
- Deep Track : This track starts from UD structures from which functional words (in particular, auxiliaries, functional prepositions and conjunctions) and surface-oriented morphological information have been removed. In addition to what has to be done for the Shallow Track, the Deep Track thus consists of the introduction of the removed functional words and morphological features.
Important Dates
↑-
Dec 11, 2017 : Registration for the task open
Dec 11, 2017 : Training and development sets available
April 9, 2018 : Evaluation scripts and Test sets available
TBD, 2018 : Human evaluation due
May 28, 2018 : Camera-ready papers due
July 19, 2018 : Workshop
Data
↑ The datasets are derived from the Universal Dependency treebanks V2.0, that is, from the data used for the CoNLL'17 shared task on Multilingual Parsing from Raw Text to Universal Dependencies.Licensing: The Dutch, English, Finnish, French, Portuguese and Spanish datasets are released under the CC BY-SA license for all languages. The Arabic, Czech, Italian and Russian datasets are released under the CC BY-NC-SA license. Please refer to the original page of the Universal Dependency treebanks V2.0 for more details on the original datasets and their licensing.
Format: Following the source datasets, the inputs to the Shallow and Deep Tracks are distributed in the 10-column CoNLL-U format.
| Training and development data: Download |
| Evaluation data: Download |
| Documentation: Open |
| Paper about dataset (INLG 2018): Download |
| System outputs: Download |
For the input to the Shallow Track, the UD structures are processed as follows:
- the information on word order is removed by randomized scrambling;
- the words are replaced by their lemmas.
For the Deep Track, additionally:
- functional prepositions and conjunctions that can be inferred from other lexical units or from the syntactic structure are removed;
- determiners and auxiliaries are replaced (when needed) by attribute/value pairs, as, e.g., Definiteness, Aspect, and Mood;
- edge labels are generalized into predicate argument labels in the PropBank/NomBank fashion;
- morphological information coming from the syntactic structure or from agreements is removed;
- fine-grained PoS labels found in some treebanks are removed, and only coarse-grained ones are maintained.
See the Examples Section below for sample structures.
Evaluation
↑ The test data can be downloaded here: Download. The compressed folder contains the templates to fill with the system outputs. If you submit outputs for both tracks, please submit two distinct folders, one for each track.We perform both automatic and manual evaluations of the outputs of the systems. For the automatic evaluation, we compute scores with the following metrics:
For each metric, we calculate (i) system-level scores (if the metric permits it), and (ii) the mean of the sentence-level scores. Output texts are normalized prior to computing metrics by lower-casing all tokens, removing any extraneous whitespace characters and ensuring consistent treatment of ampersands.
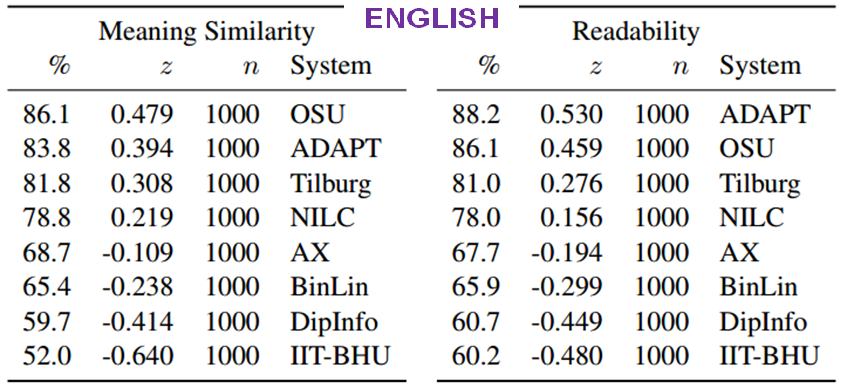
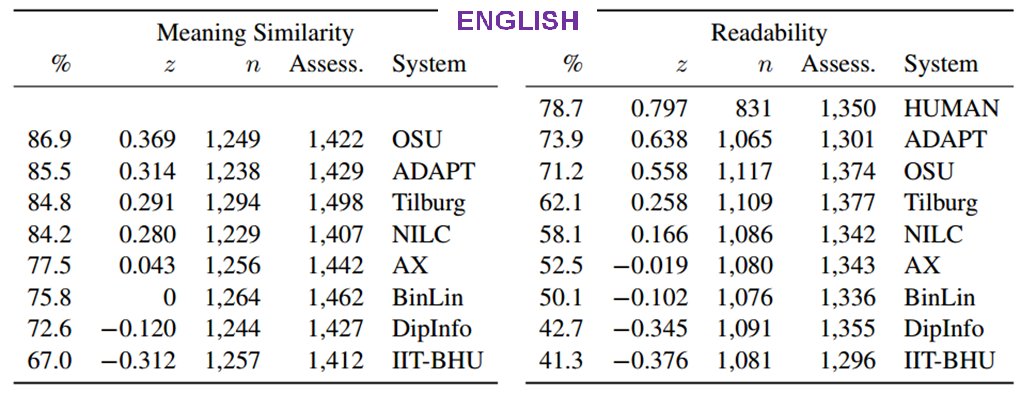
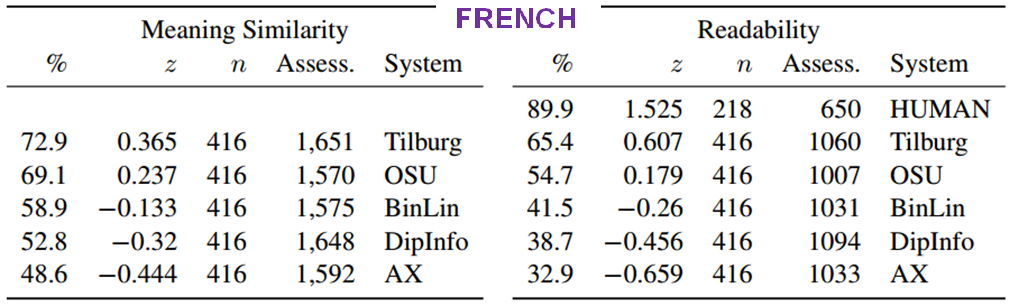
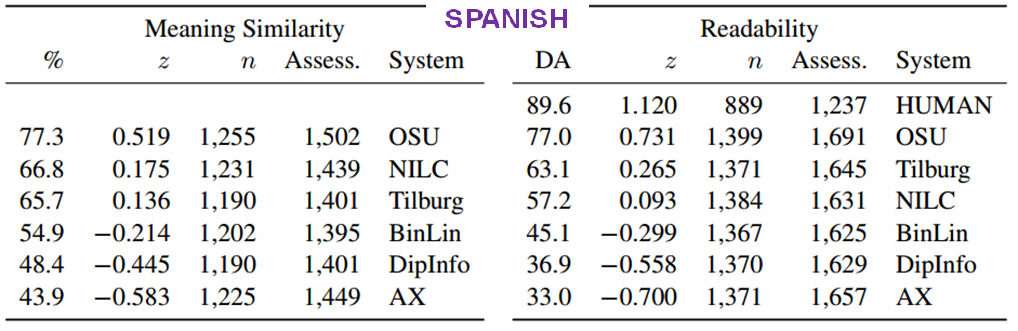
For the human-assessed evaluation, the evaluators are trained annotators in the case of the Google Data Compute evaluation, and crowdsourced annotators in the case of the Mechanical Turk evaluation. They assess sentences for Readability and Meaning Similarity with respect to a reference sentence. Quality insurance mechanisms ensure the quality of the collected annotations.
Running the evaluation scripts
The evaluation scripts can be downloaded here:
Requirements: Python 2.7 or 3.4 and NLTK. For a clean environment virtualenv can be used:
Mac OS / Ubuntu
Windows
The [system-dir] folder contains the output of the system and the [reference-dir] folder contains the reference sentences. The evaluation script uses each file found in the system director [system-dir] to look up a file with the same name in the reference directory and applies BLEU, NIST and normalized edit distance to it.
Results
↑ 21 teams registered for the task , and 8 sumbitted results: ADAPT, AX, IIT-BHU, OSU, NILC, Tilburg, DipInfo-UniTo and BinLin. The descripion of the systems and the task overview and results can be found in the MSR workshop proceedings.Automatic evaluation results:
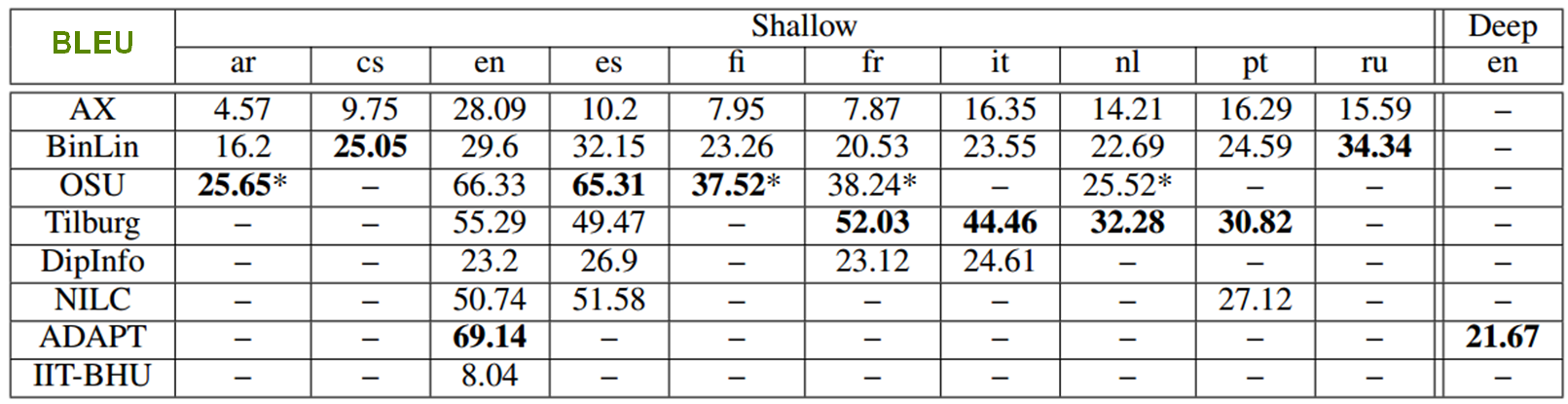

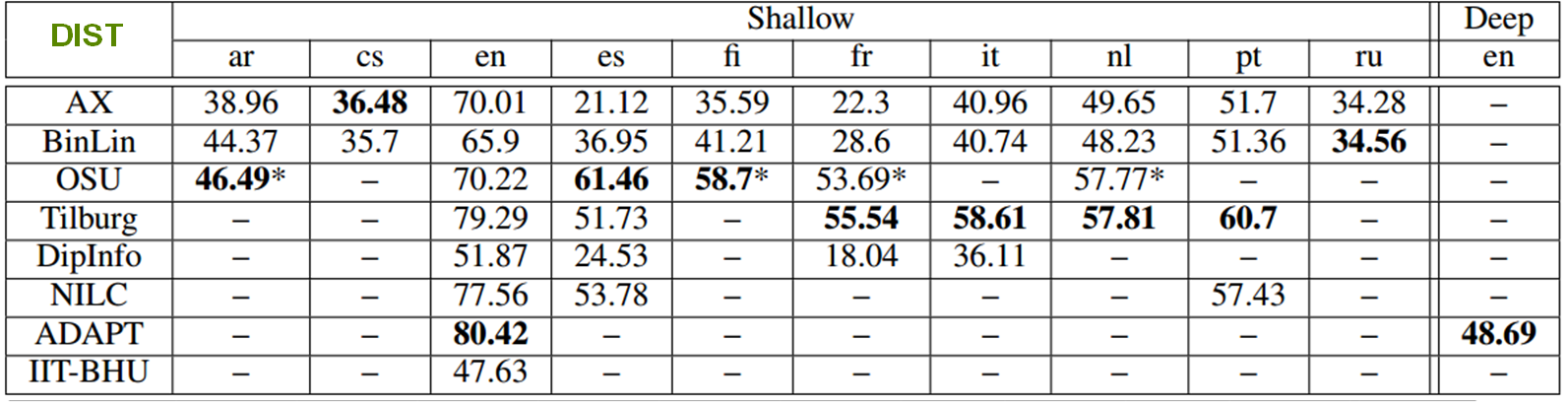
Human evaluation results - Google Data Compute:
Human evaluation results - Mechanical Turk:
Information
↑ 03/0602/10
01/10
@inproceedings{mille-EtAl:2018:MSR-SR,
title={The {F}irst {M}ultilingual {S}urface {R}ealisation {S}hared {T}ask ({SR}'18): {O}verview and {E}valuation {R}esults},
author={Mille, Simon and Belz, Anja and Bohnet, Bernd and Graham, Yvette and Pitler, Emily and Wanner, Leo},
booktitle={Proceedings of the 1st Workshop on Multilingual Surface Realisation (MSR), 56th Annual Meeting of the Association for Computational Linguistics ({ACL})},
address={Melbourne, Australia},
pages={1--12},
year={2018},
}
20/04
09/04
19/03
Registration and Submission
↑ The task is now over!Output specification
Teams are supposed to submit a single text file (UTF-8 encoding) in the format appended below, aligned with the respective input files. All output sentences have to start with the text marker '# text = ', and be preceded by the sentence ID ('# sent_id ='). In other words:
-
# sent_id = [id]
# text = [sentence]
- # any comment
# sent_id = 1
# text = From the AP comes this story :
# sent_id = 2
# text = President Bush on Tuesday nominated two individuals to replace retiring jurists on federal courts in the Washington area.
Number of outputs
We allow one output per system; each team is allowed to submit several different systems, but please avoid submitting variations of what is essentially the same system. We may have to limit each team to a single nominated system for the human evaluations.
Examples
↑ The structures for Track 1 and 2 are connected trees; the data has the same columns as the original CoNLL-U format; however, for the SR'18, the reference (original) sentences are stored in separate files, aligned with the respective structures.English
Sample original CoNLL-U file for English:

Sample Track 1 Input for English (CoNLL-U):

Sample Track 1 Input for English (graphic):
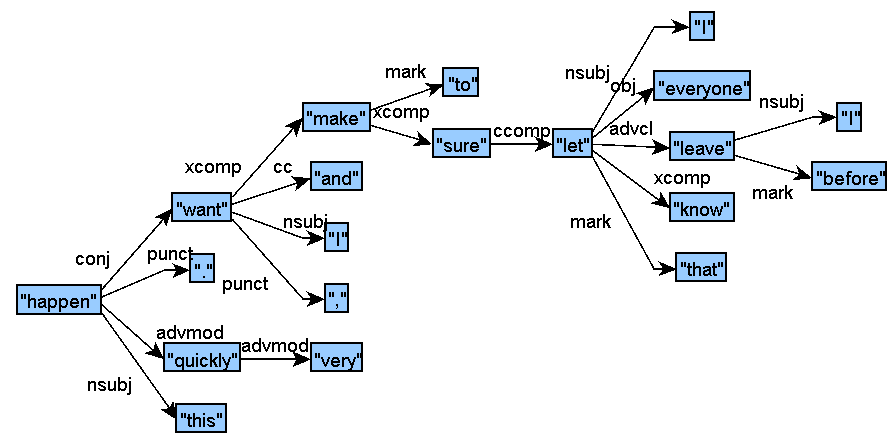
Sample Track 2 Input for English (CoNLL-U):
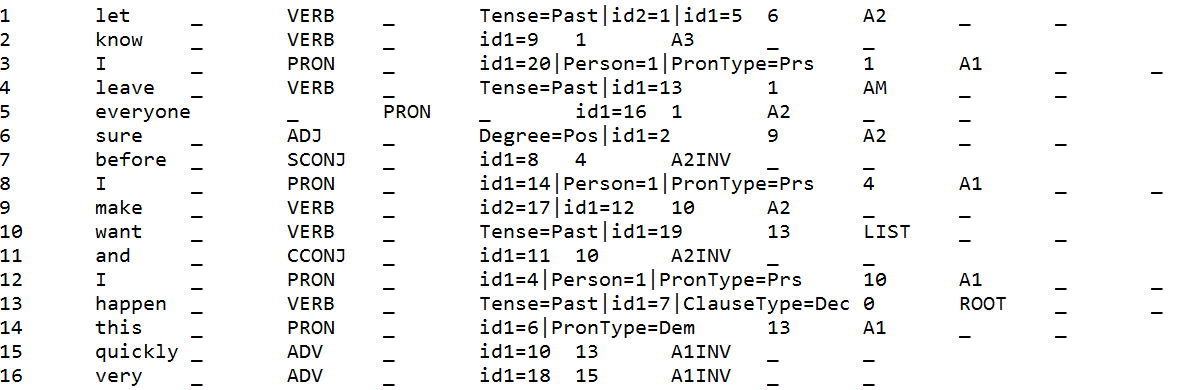
The nodes of the Track 2 structures are aligned with the nodes of the Track 1 structures through the attributes id1, id2, id3, etc. Each node can correspond to 0 to 6 superficial nodes. More examples of multiple correspondences are shown in the French and the Spanish examples, in particular with the auxiliary and case relations.
Sample Track 2 Input for English (graphic):
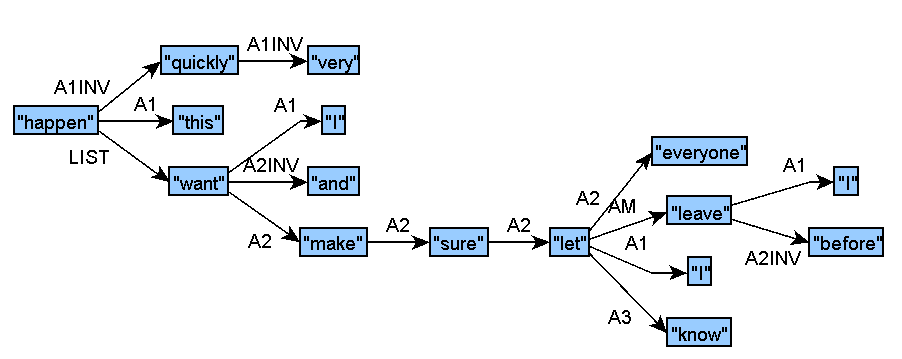
French
↑ Sample original CoNLL-U file for French; The charges laid against Kadhafi will be officially abandoned when the Court receives the evidence that he was killed last October 2nd:

Sample Track 1 Input for French (CoNLL-U):

Sample Track 1 Input for French (graphic):
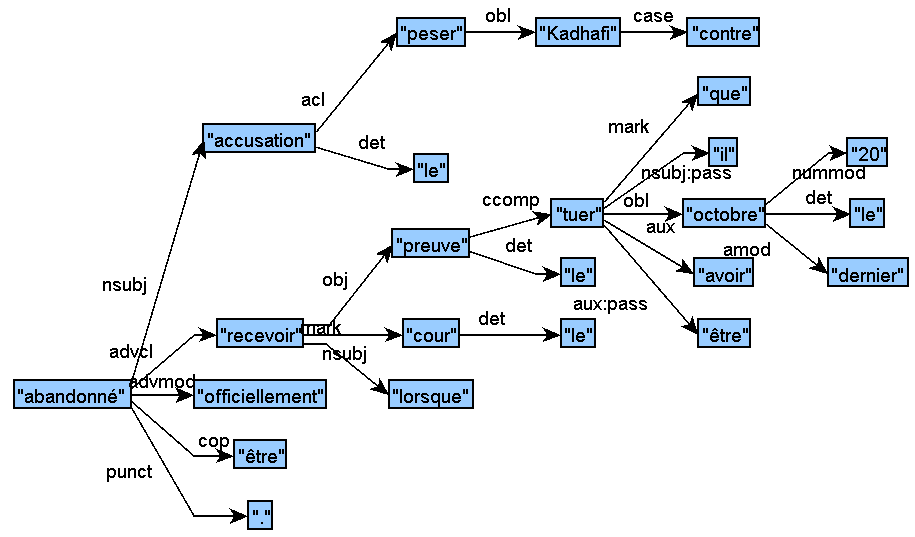
Sample Track 2 Input for French (CoNLL-U):
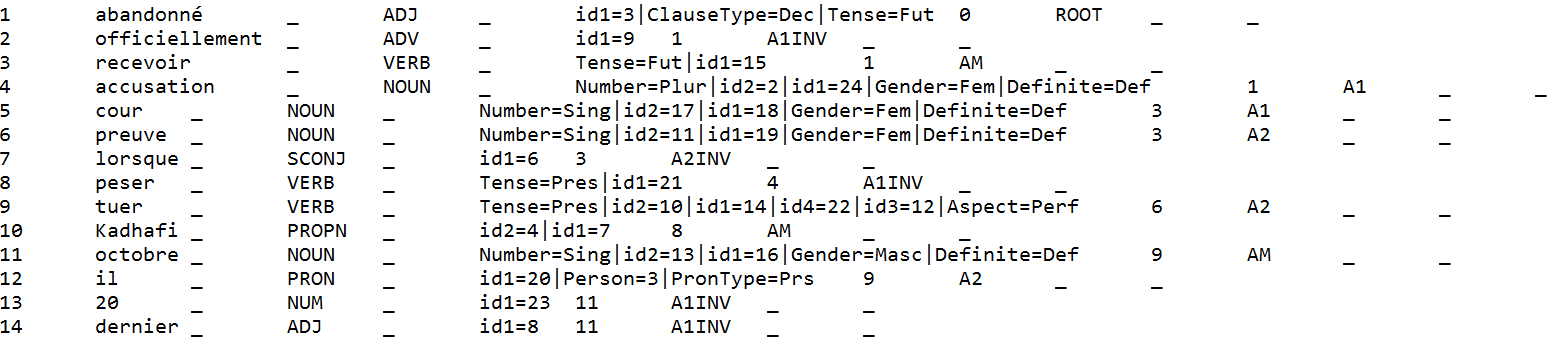
Sample Track 2 Input for French (graphic):
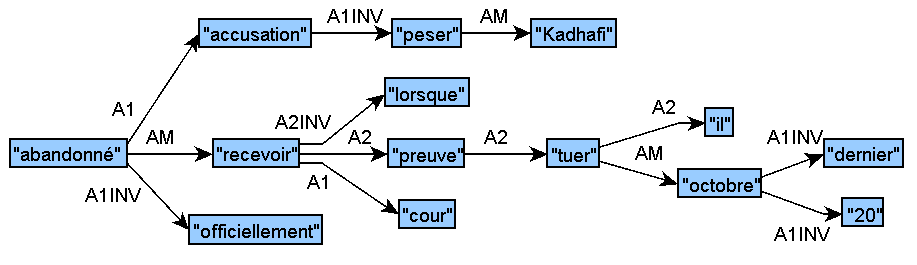
Spanish
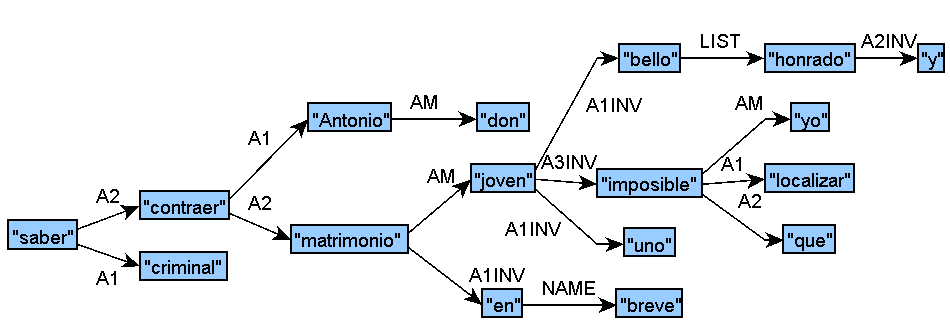
↑ Sample original CoNLL-U file for Spanish; The criminal has been able to know that Don Antonio was going to marry shortly a beautiful and honest young woman, whom we have been unable to locate:
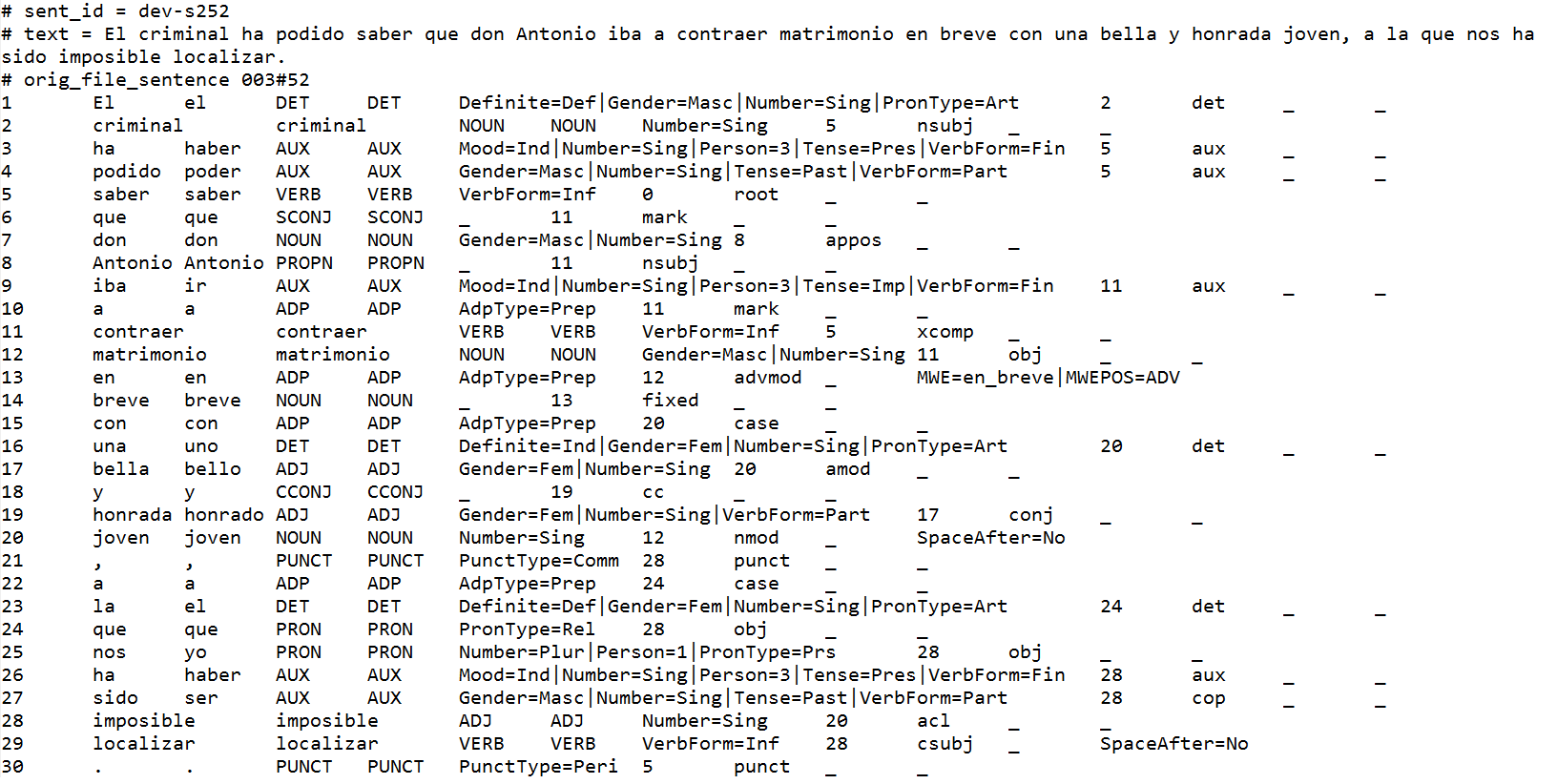
Sample Track 1 Input for Spanish (CoNLL-U):
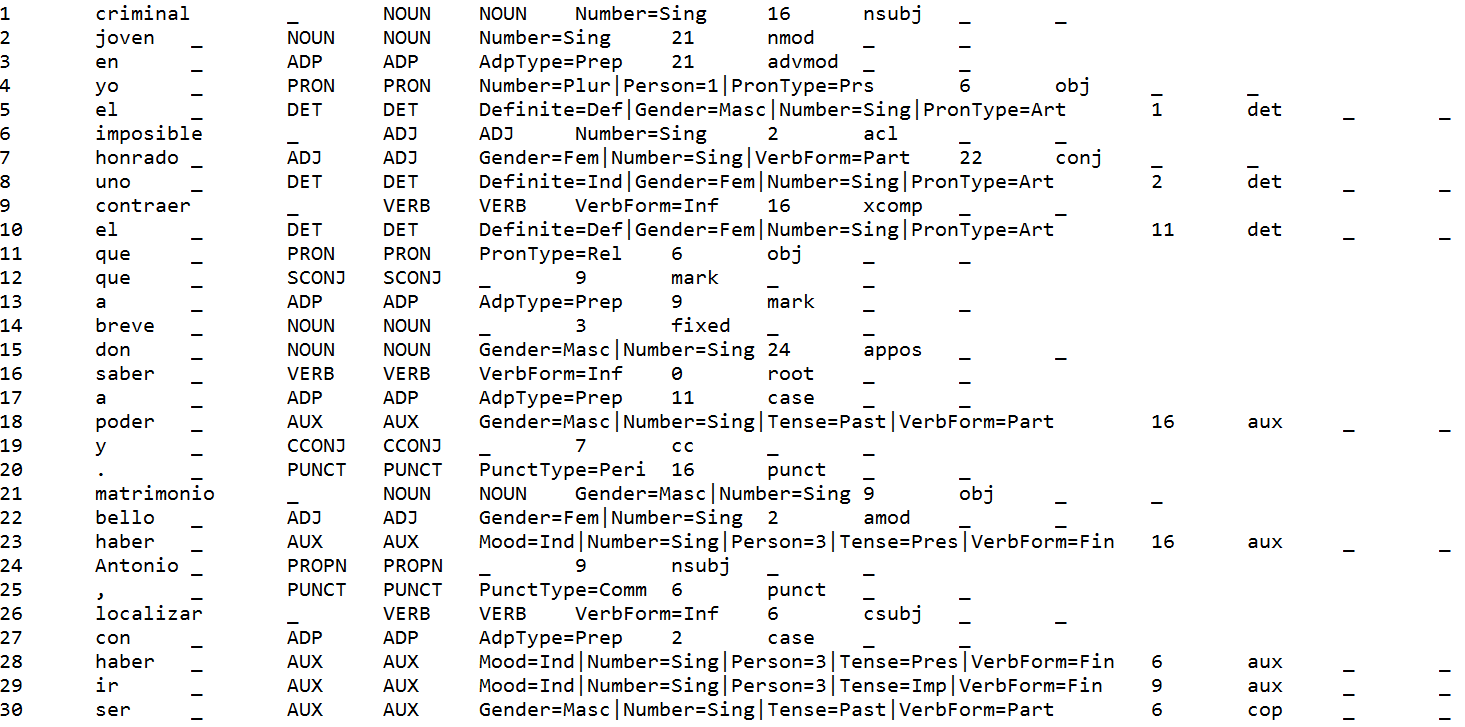
Sample Track 1 Input for Spanish (graphic):
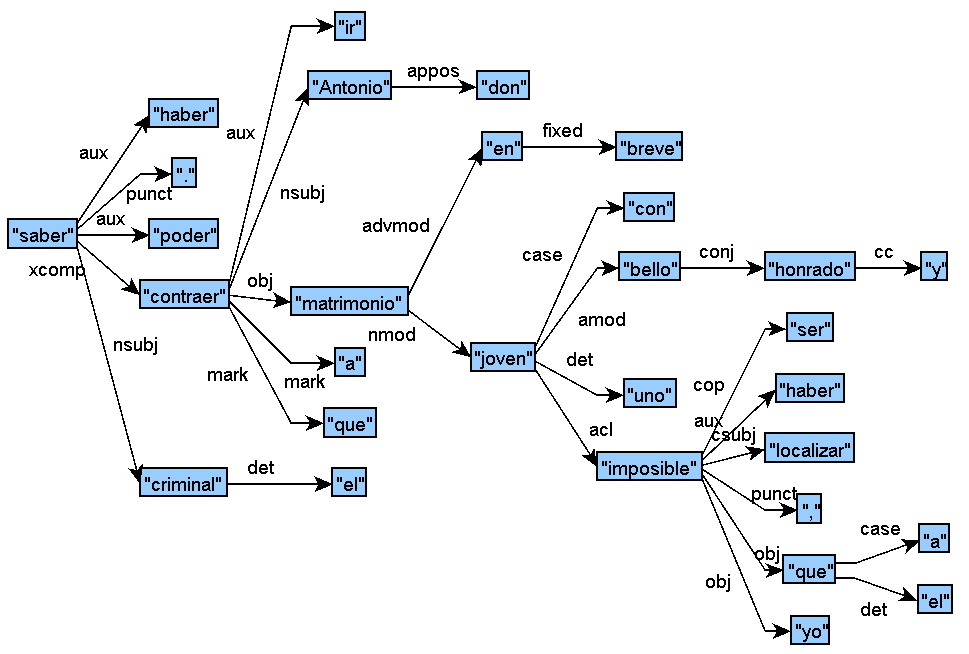
Sample Track 2 Input for Spanish (CoNLL-U):
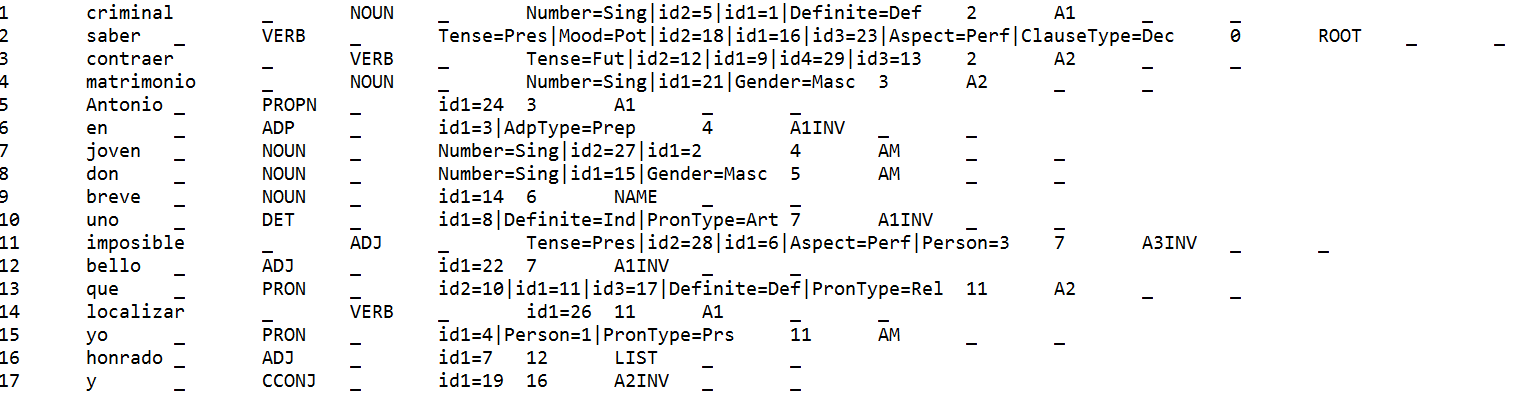
Sample Track 2 Input for Spanish (graphic):
Event
↑ The results of the Surface Realization Shared Task 2018 were presented during the Multilingual Surface Realization Workshop at ACL 2018.A previous pilot surface realization task has been run in 2011 (Pilot SR'11) as part of Generation Challenges 2011 (GenChal’11), which was the fifth round of shared-task evaluation competitions (STECs) involving the generation of natural language. The results session for all GenChal’11 tasks was held as an integral part of ENLG’11 in Nancy which attracted around 50 delegates. GenChal’11 followed four previous events: the Pilot Attribute Selection for Generating Referring Expressions (ASGRE) Challenge in 2007 which held its results meeting at UCNLG+MT in Copenhagen, Denmark; Referring Expression Generation (REG) Challenges in 2008, with a results meeting at INLG’08 in Ohio, US; Generation Challenges 2009 with a results meeting at ENLG’09 in Athens, Greece; and Generation Challenges 2010 with a results meeting at INLG’10 in Trim, Ireland.