
Surface Realization Shared Task 2019
April 5th - August 19th 2019
SR'19 - SIGGEN event
- The general objective of the Surface Realization Shared Task is to provide common-ground datasets for developing and evaluating Natural Language Generation systems. The results of this second Multilingual Surface Realization Shared Task (SR'19) and the participating systems will be presented during the Multilingual Surface Realization Workshop @EMNLP 2019. The task is endorsed by the ACL Special Interest Group on Natural Language Generation (SIGGEN).
Task
- The goal of the shared task is to produce a well-formed sentence out of the given input structure. As in SR’18 and SR'11, the proposed shared task comprises two tracks with different levels of complexity:
- Shallow Track (Track 1): This track starts from genuine UD structures from which word order information has been removed and the tokens have been lemmatized, i.e., from unordered dependency trees with lemmatized nodes that hold PoS tags and morphological information as found in the original annotations. The task consists in determining the word order and inflecting the words.
- Deep Track (Track 2): This track starts from UD structures from which functional words (in particular, auxiliaries, functional prepositions and conjunctions) and surface-oriented morphological information have been removed. In addition to what has to be done for the Shallow Track, the Deep Track thus consists in introducing the removed functional words and morphological features.
- Either or both of the tracks can be addressed by the participating teams.
- New features for the SR'19 (compared to SR'18):
- Closed task: in order to improve the comparability of the results, no other annotated data than those provided by the organizers can be used for training the systems. However, it is allowed to use available parsers to create a silver standard version of the provided datasets and use them as additional/alternative training material. Furthermore, the use of some publicly available off-the-shelf language models suggested by the participants is allowed (e.g. Word2vec, ELMo, BERT, GPT-2). Please contact the organizers to suggest resources; a list will be maintained in the Data section.
- Evaluation: both in-domain and out-of-domain data can be used in the test data. For some languages, automatically parsed texts will also need to be generated.
- Data alignment : in the training sets, the Shallow data is fully aligned with the original UD structures, and the Deep data is fully aligned with both the original and Shallow structures.
- Relative word order information: relative word order information in Multiword Expressions, punctuations and multiple coordinations is available in the input.
- Multiple datasets: for some languages, there are two or more UD datasets; the teams are allowed to choose which dataset(s) they want to use for training their models.
Registration
↑-
Closed!
Important Dates
-
Note that due to a short time frame for the human evaluations, the date of the output collection will not be changed.
November 3, 2019 : Presentation of results and systems @MSR workshop
Information
-
08/10
- The program of the day is now available on the MSR workshop page.
- The dates of the workshop have been confirmed, and the results and participating systems of the shared task will be presented on November 3rd at EMNLP-IJCNLP'19.
- The anonymized results of the automatic evaluations were released to the participants.
- The task is now closed! 14 teams submitted outputs, the results of the automatic evaluations will be released in the next days.
- Additional information about the output specification has been added.
- The evaluation datasets and instructions for submission have been sent to the participants. Additional information about fine-tuning the off-the-shelf models has been provided in the Data section.
- The samples provided in the Data section have been clarified (training VS test/input samples).
- New pre-trained models suggested by participants have been added the list.
- New information about the evaluation procedure has been released.
- Additional information on the training data: It is allowed to use available parsers to create a silver standard version of the provided datasets and use them as training material.
- The shared task has been launched!
16/09
30/08
20/08
12/08
03/08
24/07
19/07
25/06
15/04
05/04
Data
↑-
Training and development data: The data is now available for direct download from the Generation Challenges (GenchChal) repository. The compressed folder contains (i) the original UD datasets for 11 languages as they can be found on the UD page (20 + 20 files); (ii) the Track 1 datasets (20 + 20 files); (iii) the Track 2 datasets (9 + 9 files); (iv) statistics about all the datasets (98 files).
Paper about SR'18 dataset (INLG 2018): Download
More informal documentation: Open
- The data used is the Universal Dependency treebanks V2.3, that is, the datasets released after the completion of the CoNLL'18 shared task on Multilingual Parsing from Raw Text to Universal Dependencies (V2.2). The inputs to the Shallow and Deep Tracks are distributed in the 10-column CoNLL-U format, and with the same licenses are the data they come from (see UD page).
- For the creating the input to the Shallow Track, the UD structures were processed as follows:
- The information on word order was removed by randomized scrambling.
- The words were replaced by their lemmas.
- Two features were added to store information about (i) relative linear order with respect to the governor (lin), and (ii) alignments with the original structures (original_id, in the training data only).
- Languages: Arabic, Chinese, English (4 datasets), French (3), Hindi, Indonesian, Japanese, Korean (2), Portuguese (2), Russian (2) and Spanish (2).

-
For the Deep Track, additionally:
- Functional prepositions and conjunctions that can be inferred from other lexical units or from the syntactic structure were removed.
- Determiners and auxiliaries are replaced (when needed) by attribute/value pairs, as, e.g., Definiteness, Aspect, and Mood.
- Edge labels were generalized into predicate argument labels in the PropBank/NomBank fashion.
- Morphological information coming from the syntactic structure or from agreements was removed.
- Fine-grained PoS labels found in some treebanks were removed, and only coarse-grained ones were maintained.
- Languages: English (4 datasets), French (3) and Spanish (2).
-
List of authorized additional resources (to be updated):
- Word2vec, including branches such as Word2veccf
- ELMo
- BERT
- GPT-2
- polyglot
- GloVe
- UD parsers such as UUParser
- The above models can be fine-tuned if needed using publicly available datasets such as WikiText and the DeepMind Q&A dataset
- Example
↑ The structures for Track 1 and 2 are connected trees; the data has the same columns as the original CoNLL-U format; however, for the SR'19, the reference sentences can be found in the original UD data. The goal of both tasks is, for each input structure, to get as close as possible to the reference sentence.
-
Sample original CoNLL-U file for English:
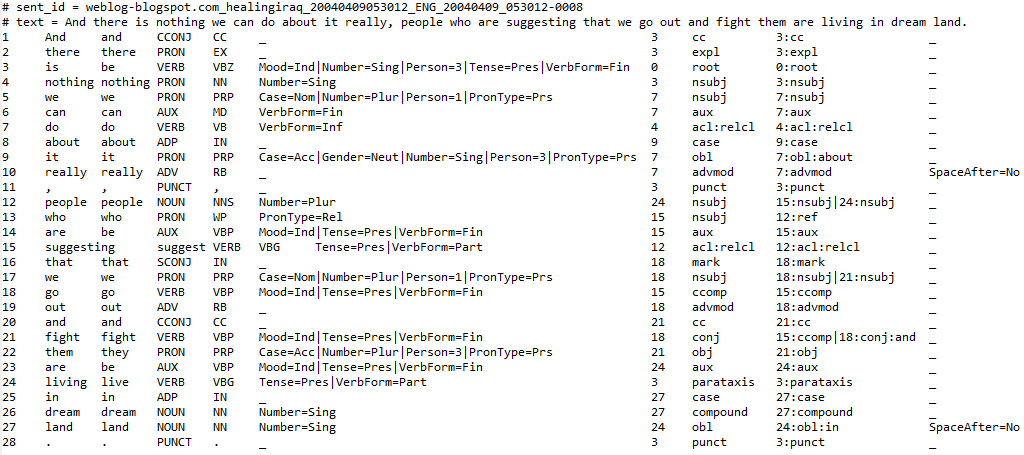
-
Track 1 training sample for English (CoNLL-U):
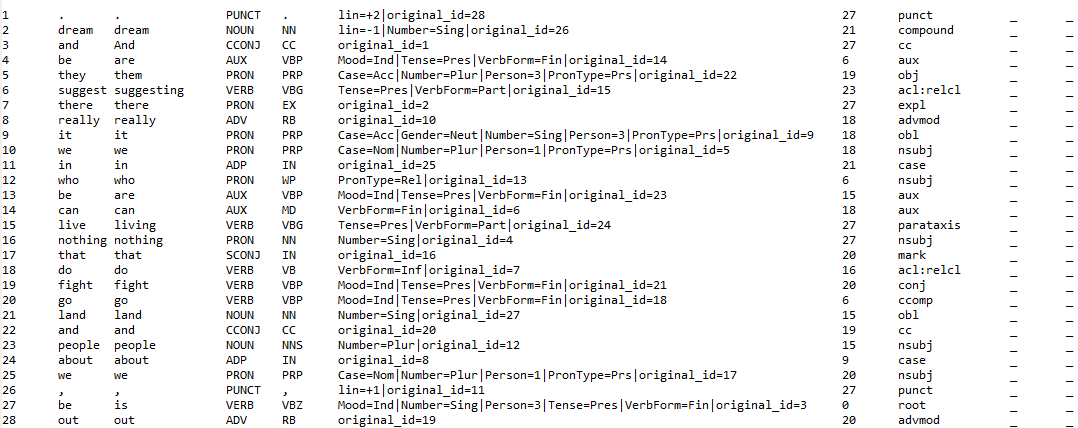
-
Track 1 input (dev/test) sample for English (CoNLL-U): the alignments with the surface tokens are not provided.
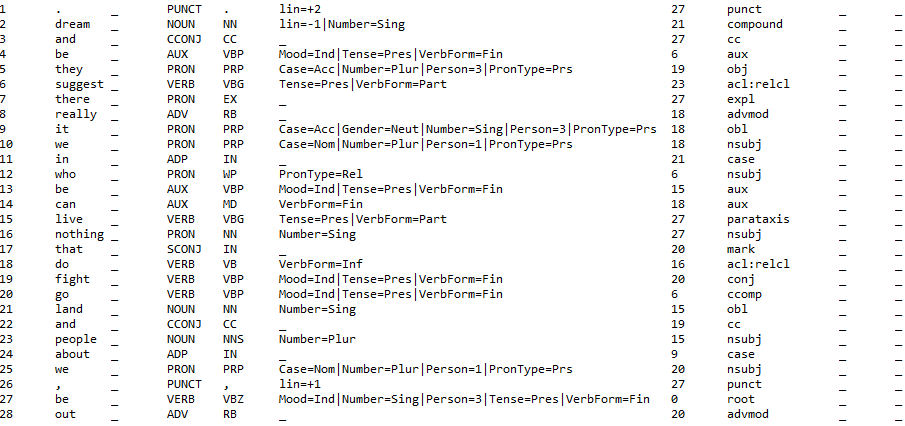
-
Track 1 sample structure for English (graphic):
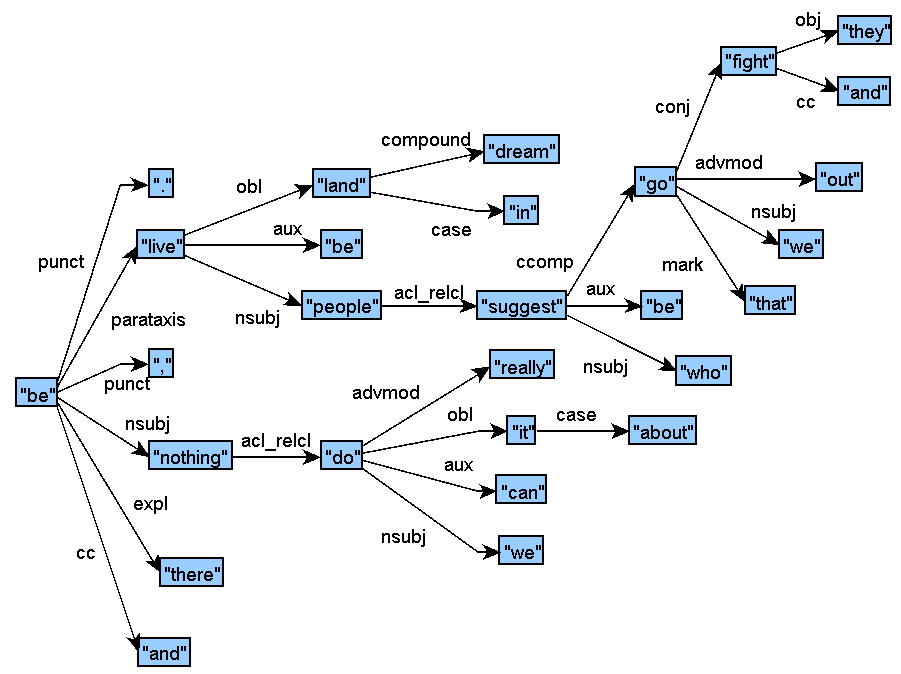
-
Track 2 training sample for English (CoNLL-U):
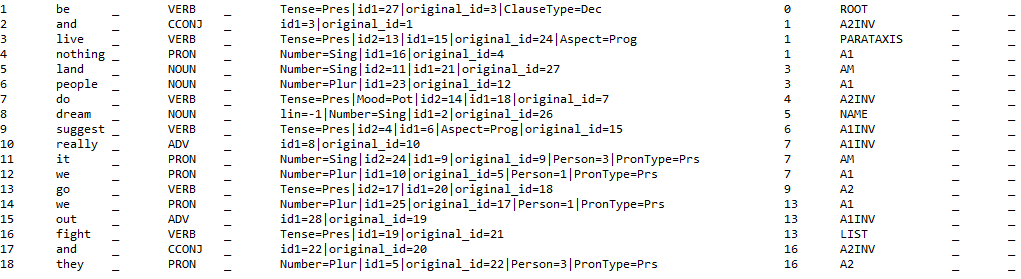
-
The nodes of the Track 2 structures are aligned with the nodes of the Track 1 structures through the attributes id1, id2, id3, etc. Each node can correspond to 0 to 6 superficial nodes; multiple node correspondences involve in particular dependents with the auxiliary, case, det, or cop relations.
-
Track 2 input (dev/test) sample for English (CoNLL-U): the alignments with the surface and Track 1 tokens are not provided.
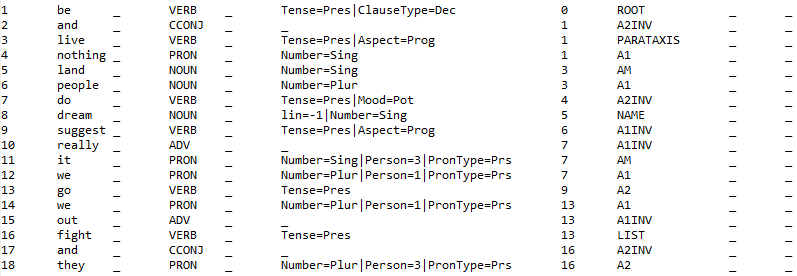
-
Track 2 sample structure for English (graphic):
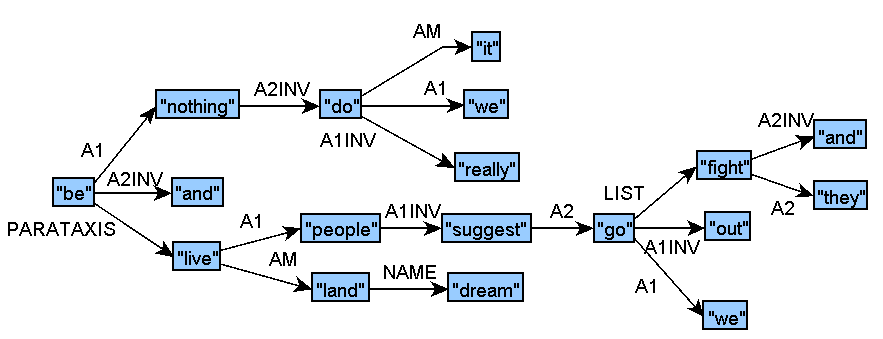
Evaluation
↑-
Once the evaluation results are available, each team will be asked if the results of their system can be released publicly, and if not, will have the possibility to anonymize their team name, which implies not publishing a system description paper.
- BLEU: precision metric that computes the geometric mean of the n-gram precisions between generated text and reference texts and adds a brevity penalty for shorter sentences. We use the smoothed version and re-port results for n= 1,2,3,4.;
- NIST: related n-gram similarity metric weighted in favour of less frequent n-grams which are taken to be more informative;
- Normalized edit distance: inverse, normalized, character-based string-edit distance that starts by computing the minimum number of character inserts, deletes and substitutions(all at cost 1) required to turn the system output into the (single) reference text.
For the evaluation, this year we will ask for both tokenized (for automatic evaluation) and detokenized (for human and possibly automatic evaluation) outputs. If no detokenized outputs are provided, the tokenized files will be used for human evaluation. Inputs from both in-domain and out-of-domain data will be found in the evaluation material.
For human evaluation, which is the primary evaluation method, we will use direct assessment (Graham et al., 2016) of system outputs. Candidate outputs will be presented to human assessors who rate their (i) meaning similarity (relative to a gold sentence) and (ii) readability (no gold sentence presented) on a 0-100 rating scale. Systems will be ranked according to average ratings.
For the automatic evaluation, we will compute scores with the following metrics:
For each metric, we calculate (i) system-level scores (if the metric permits it), and (ii) the mean of the sentence-level scores. Output texts are normalized prior to computing metrics by lower-casing all tokens, removing any extraneous whitespace characters and ensuring consistent treatment of ampersands.
For a subset of the test data we may obtain additional alternative realizations via Mechanical Turk for use in the automatic evaluations.
-
Running the evaluation scripts
- SR19-eval (Compatible with Python 2 and Python 3)
-
Python 2.7 -
Python 3.4 - Create virtual environment for python: 'virtualenv nx'.
- Activate the virtual environment: 'source nx/bin/activate'.
- Installing NLTK: 'pip install -U nltk'.
- Command line: python eval_Py2.py [system-dir] [reference-dir].
- Use eval_Py3.py instead of eval_Py2 if you use Python 3.4 or above.
- Installing NLTK: 'pip install -U nltk'. In order to use pip, you may need to navigate to the directory that contains pip.exe through the command line before running the command.
- Command line: eval_P2.py [system-dir] [reference-dir].
- Use eval_Py3.py instead of eval_Py2 if you use Python 3.4 or above.
NOTE: The scripts initially released below, which were available to the participants during the task, produced an erroneous DIST score. Thanks to Yevgeniy Puzikov for detecting the problem! The updated script (SR19-eval) fixes the issue, and has been made compatible with Python 2 and 3. The evaluation scripts can be downloaded here:
Requirements: Python 2.7 or 3.4 and NLTK. For a clean environment virtualenv can be used:
Mac OS / Ubuntu
Windows
The [system-dir] folder contains the output of the system and the [reference-dir] folder contains the reference sentences. The evaluation script uses each file found in the system director [system-dir] to look up a file with the same name in the reference directory and applies BLEU, NIST and normalized edit distance to it.
Note that in some cases, there are problems getting the correct NIST score with Python 3, so it is recommended to use the Python 2 script. The scores from last year are available on the SRST18 results page.
Submission
↑-
Submission of the results
- tokenized sample (Spanish dev example): #text = Elías Jaua , miembro del Congresillo , considera que los nuevos miembros del CNE deben tener experiencia para " dirigir procesos complejos " .
- detokenized sample (Spanish dev example) : #text = Elías Jaua, miembro del Congresillo, considera que los nuevos miembros del CNE deben tener experiencia para "dirigir procesos complejos".
The participating teams should send a .zip file with the outputs to msr.organizers@gmail.com by August 19th at 11:59 PM GMT -12:00, following the specifications detailed below.
System description papers
After receiving the evaluations, if a team decides to make their results public, they are expected to write a paper to describe their system and discuss the results. The papers should be uploaded on START by September 9th A link to the START page will be provided a few weeks before the due date.
Output specification
Teams are supposed to submit a single text file (UTF-8 encoding) per input test set in the format appended below, aligned with the respective input files. All output sentences have to start with the text marker '#text = ', and be preceded by the sentence ID ('#sent_id ='). In other words:
-
#sent_id = [id]
#text = [sentence]
Example:
- #any comment
#sent_id = 1
#text = From the AP comes this story :
#sent_id = 2
#text = President Bush on Tuesday nominated two individuals to replace retiring jurists on federal courts in the Washington area.
A file that contains both the sentence IDs aligned with the test data and the empty '#text' field will be provided to the participants . For null outputs, the '#text = ' field should remain empty.
Please provide both tokenized (for automatic evaluations) and detokenized (for human evaluations) outputs; if no detokenized outputs are provided, the tokenized files will also be used for the human evaluation.
The submissions should be compressed and the name of the .zip folder that you send should include the official team name. As output file names, use the same name as the input file, with the .txt extension: en_ewt-ud-test.conllu -> en_ewt-ud-test.txt. Make sure to keep the tokenized, detonekized, T1 and T2 outputs in separate and clearly labeled folders
Finally, you may be aware that it is possible to obtain the reference sentences for most of the datasets used in this evaluation; obviously, it is not allowed to use them in any way for generating the outputs.
Number of outputs
We allow one output per system; each team is allowed to submit several different systems, but please avoid submitting variations of what is essentially the same system. We may have to limit each team to a single nominated system for the human evaluations.
History
↑-
In 2018, the first edition of the workshop took place in Melbourne, Australia, in collocation with ACL'18. Eight teams participated to the shared task and to the workshop. The proceedings of the workshop with the system descriptions and the task overview and results can be found in the MSR'18 workshop proceedings.
A previous pilot surface realization task had been run in 2011 (Pilot SR'11) as part of the Generation Challenges 2011 (GenChal’11), which was the fifth round of shared-task evaluation competitions (STECs) involving the generation of natural language. The results session for all GenChal’11 tasks was held as an integral part of ENLG’11 in Nancy which attracted around 50 delegates. GenChal’11 followed four previous events: the Pilot Attribute Selection for Generating Referring Expressions (ASGRE) Challenge in 2007 which held its results meeting at UCNLG+MT in Copenhagen, Denmark; Referring Expression Generation (REG) Challenges in 2008, with a results meeting at INLG’08 in Ohio, US; Generation Challenges 2009 with a results meeting at ENLG’09 in Athens, Greece; and Generation Challenges 2010 with a results meeting at INLG’10 in Trim, Ireland.
Contact
- If you have any question or comment, please write to us: msr.organizers@gmail.com .
- The shared task is organized by the Multilingual Surface Realization workshop committee: Anja Belz, Bernd Bohnet, Yvette Graham, Simon Mille and Leo Wanner.
References
- Anja Belz, Michael White, Dominic Espinosa, Eric Kow, Deirdre Hogan, and Amanda Stent. 2011. The first surface realisation shared task: Overview and evaluation results. In Proceedings of the 13th European Workshop on Natural Language Generation, ENLG ’11, pages 217–226, Stroudsburg, PA, USA. Association for Computational Linguistics.
- Yvette Graham, Timothy Baldwin, Alistair Moffat and Justin Zobel. 2016. Can Machine Translation Systems be Evaluated by the Crowd Alone? In Journal of Natural Language Engineering (JNLE), Firstview.
- Simon Mille, Anja Belz, Bernd Bohnet, Leo Wanner. 2018. Underspecified Universal Dependency Structures as Inputs for Multilingual Surface Realisation. In Proceedings of the 11th International Conference on Natural Language Generation, 199-209, Tilburg, The Netherlands.
- Simon Mille, Anja Belz, Bernd Bohnet, Yvette Graham, Emily Pitler, Leo Wanner. 2018. The First Multilingual Surface Realisation Shared Task (SR'18): Overview and Evaluation Results. In Proceedings of the 1st Workshop on Multilingual Surface Realisation (MSR), 56th Annual Meeting of the Association for Computational Linguistics (ACL), 1-12, Melbourne, Australia.
Funding
- (1) Science Foundation Ireland (sfi.ie) under the SFI Research Centres Programme co-funded under the European Regional Development Fund, grant number 13/RC/2106 (ADAPT Centre for Digital Content Technology, www.adaptcentre.ie) at Dublin City University;
(2) the Applied Data Analytics Research & Enterprise Group, University of Brighton, UK; and
(3) the European Commission under the H2020 via contracts to UPF, with the numbers 825079-STARTS, 779962-RIA, 700475-IA, 7000024-RIA.
Photo at the top of the page by Chris Lawton on Unsplash.